Optimizing Business with Digital Innovation
Get Started
50+
Clients
100+
Projects
10+
Industries
14+
Awards &
Partnerships
Talent
Solutions
Optimize your workforce management and drive organizational success.
Let's Talk
Digital Consulting & Delivery
Differentiate yourself from your competition through innovative collaboration and streamlined processes.
Got a project?
Data & AI
We transform raw data into powerful insights and intelligent solutions.
Get Started
Empowering Service for Over 12M Users
Metova, with expertise in mobile app development and backend support, provided a comprehensive solution.
Get in Touch
Our holistic approach to strategy, design, and engineering will unlock your organization’s full potential. Our team of experts collaborates with you and your team to innovate, streamline processes, and differentiate yourself from your competition.
Our cutting-edge data & AI services transform raw data into powerful insights and intelligent solutions. We specialize in creating customized data products that leverage advanced analytics, machine learning, and AI models to address your specific business challenges.
Our comprehensive talent solutions optimize workforce management and drive organizational success. From talent acquisition and employee engagement to workforce planning and PEO services, our tailored offerings help you choose solutions that cost-effectively build and maintain high performance.
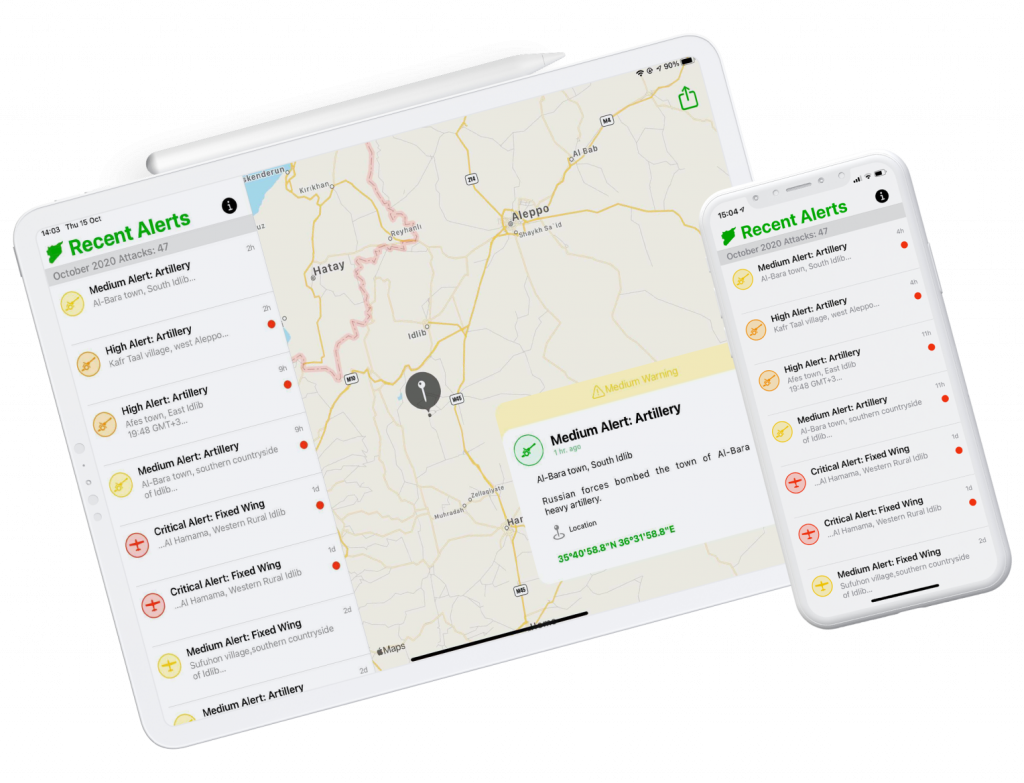
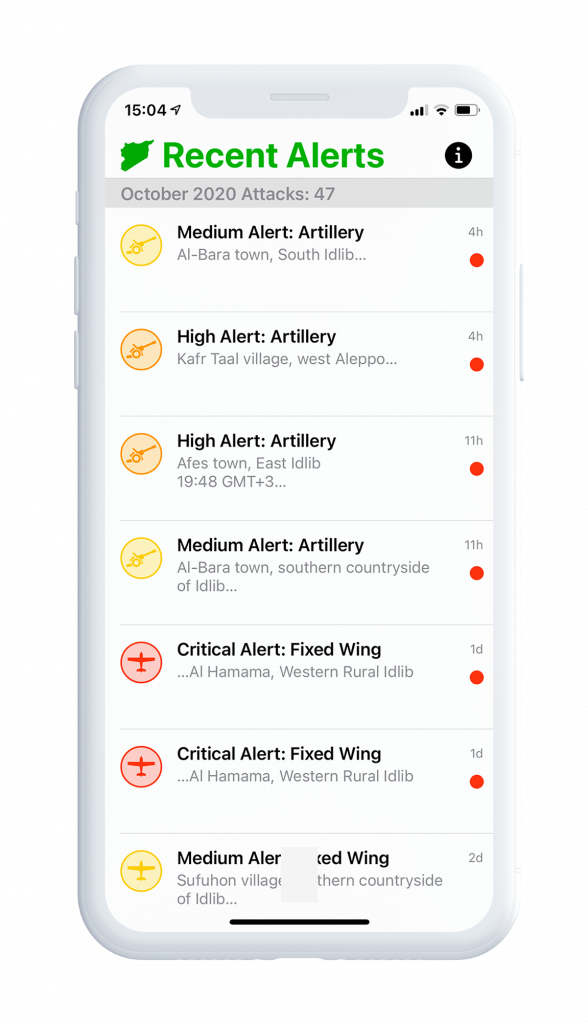
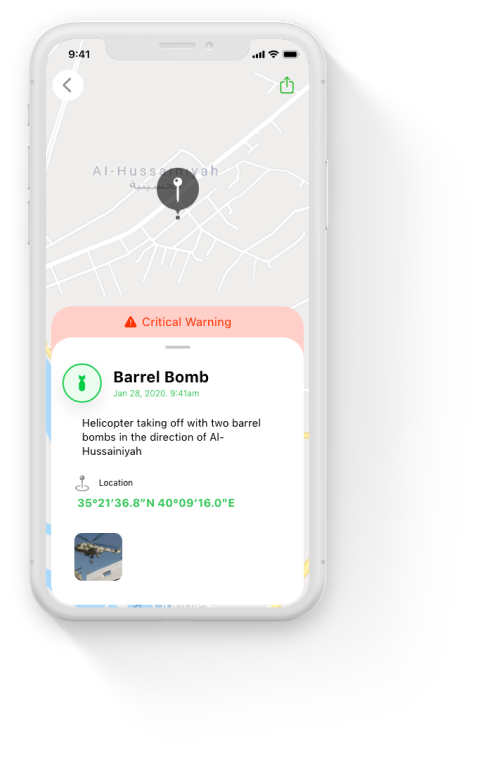
The Syrian Emergency Task Force is a U.S.-based humanitarian non-profit pursuing justice, democracy, and peace in Syria.
Metova built native mobile applications to be used as a platform for the SETF team to broadcast this critical information as well as to create a channel for the public to receive information
Metova’s key development challenge was to design and build an easy to use application that could be used by both sides, the SETF team and the public in general. All while having time and resource limitations bound by the volunteer effort by Metova and the limited bandwidth of the SETF team.
Metova started reviewing the source code in the MyBambu mobile and web applications in May of 2019, and we found that the state of the source code did not align with the launch date that MyBambu was targeting.
Metova produced a plan for remediation, identifying which issues were a priority to fix immediately, which issues could be fixed in the next few weeks, and which issues could be put off until after launch.
Metova has successfully been able to build out the features that MyBambu requested be in the application for launch and assisted through the development, design, distribution, and ultimate launch of the native MyBambu mobile application for iPhone and Android.
We work relentlessly to identify customer needs, define and build new experiences, align business goals, streamline workflows and drive revenue — while staying focused on delighting customers.
All 5 phases of our transformation process work together, beginning with research and strategy, collaborating with design, delivering with development, finalizing with quality assurance – and launching with marketing services.
From mobile apps and websites to sensor networks and connected things, we’ve built on both hardware and software since 2006 and can help you to leverage technology in your busines
That’s why Human Resources is committed to maintaining a high level of employee satisfaction, experience and opportunity, providing leadership in shaping an equitable and inclusive workplace that drives diversity, excellence and innovation.
Since our beginning, we have strived to create an outstanding identity centered on our people working through an open culture, characterized by our core values and client service, to generate a positive impact on our people, our clients, our suppliers and our communities to make an impact on their lives.
Since our beginning, we have strived to create an outstanding identity centered on our people working through an open culture, characterized by our core values and client service, to generate a positive impact on our people, our clients, our suppliers and our communities to make an impact on their lives.
Metova is a Kantata Implementation Partner (formerly Mavenlink).
We can change the way you do business.
Kantata helps you do what you do.
Only better.
Kantata’s utilization reports, capacity planning reports, and a wide variety of customized reports help managers create the critical project and resource updates they need with no coding.
Serve your clients with the power of The Kantata Industry Cloud for Professional Services™.
We love pizza, coffee, and beautiful design & super usable products. We’re always open to new creative, analytical, and technical minds to join our team.